AI Tool

Synthesia
Synthesia
Synthesia
AI avatar video platform that turns scripts into professional talking-head videos in 140+ languages — the corporate training standard.
AI avatar video platform that turns scripts into professional talking-head videos in 140+ languages — the corporate training standard.
Synthesia was founded in 2017 in London by a research team that included Victor Riparbelli, Steffen Tjerrild, Lourdes Agapito, and Matthew Ritchie. The founding premise was academic before it was commercial: the team was working on neural-rendering research that could synthesize realistic human video from text. What looked like a research curiosity in 2017 became a product problem by 2020 — and when the pandemic hit and every enterprise on earth suddenly needed video content without access to studios or presenters, the timing was perfect.
By 2021 Synthesia had raised $12.5M in Series A funding and launched a self-serve product. By 2023 they’d crossed $50M ARR and raised a $90M Series C led by Accel at a $1B valuation. The customer list by then included Google, Nike, Reuters, BBC, and Amazon — a who’s who of organizations that need to produce enormous volumes of training, onboarding, and communications video at a pace that traditional production can’t match.
The product has always had one clear thesis: the bottleneck in corporate video is production cost and turnaround time, not creative ambition. Most training videos are talking heads explaining a process. Most corporate comms are an executive saying something everyone needs to hear. You don’t need a cinematographer for that. You need a fast pipeline from script to polished output, delivered at global scale. Synthesia built exactly that pipeline, and in 2026 it remains the company whose name L&D teams drop first when the subject of AI video comes up.
The company is headquartered in London with offices in New York and operates as a pure-SaaS platform — no desktop software, everything lives in the browser. As of 2026 they report over one million users across Fortune 100 companies, with the platform generating more than 20 million videos since launch.
Strip away the marketing and Synthesia is a browser-based video editor where the “presenter” is an AI avatar instead of a human. You write a script, choose an avatar from a library of 240+ diverse stock characters, pick a language and voice, drop in slides or screen recordings as background context, and hit generate. A few minutes later you have a polished video with a lip-synced avatar delivering your script — no camera, no studio, no green screen.
That’s the core loop. But the platform has grown considerably beyond it. The main components in 2026:
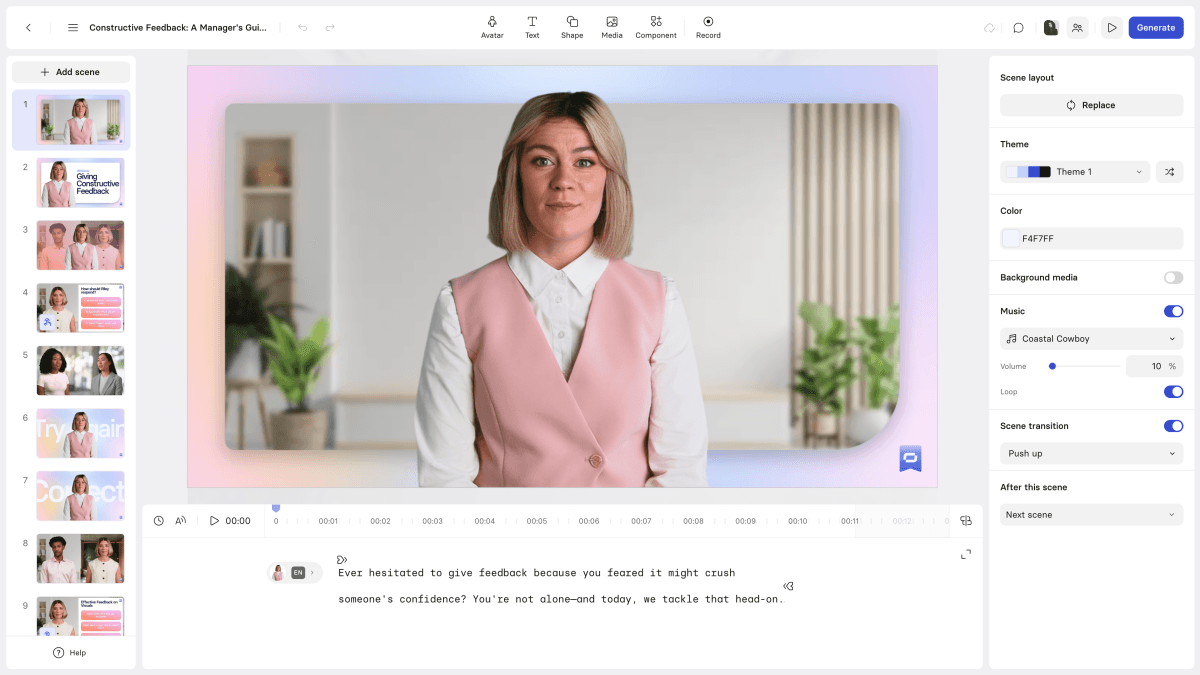
The signup is frictionless — free tier, no credit card. The dashboard is browser-native and clean: a project grid, a template browser, and a prominent “New Video” button. For anyone who’s spent time in video editing software, the absence of a timeline is immediately noticeable. There is no timeline. You work in a slide-based editor: each scene is a card with an avatar, background, and script text. Duration is determined by how much text you write.
The first thing most new users do is wrong: they pick a template and immediately start typing a long script. The better move is to use the AI Script Generator first. Paste your training doc, a URL, or even just a topic sentence and let the generator produce a structured draft with headers and scene breaks. It takes a minute and saves you the cognitive load of thinking in “video scenes” before you know what the output looks like.
Pick an avatar. The selection UI lets you filter by gender, age, ethnicity, and style (professional, casual, etc.). Expressive avatars are flagged clearly — they move and gesture as they speak, which reads considerably more naturally than static stock avatars. Preview any avatar speaking a sample line before committing. The preview renders in seconds.
Hit generate on a three-scene test video. Wait roughly two to four minutes. The output is an MP4 with your avatar speaking your script, lips in sync, with background visuals and auto-captioning. For a first experience, the result typically surprises people on the upside — this is a long way from the stiff, mechanical AI videos of 2021. The uncanny valley is narrower but still present in closeups; the avatars work best in medium-shot framing, which most templates default to.
Synthesia applies avatar voice and language settings per scene. Set the language at the project level before you start adding scenes — changing it mid-project requires re-generating each scene individually. One configuration decision upfront saves significant time later.
Synthesia’s avatars exist on a hierarchy that’s important to understand before committing to a plan. Picking the wrong tier means paying for avatars you can’t access — or discovering the avatar you want is an Enterprise-only add-on after you’ve built a whole project around it.
The base library. 240+ diverse characters with professional presentation styles, available from the free tier (limited to 9) through paid plans (125+ on Starter, 180+ on Creator, 240+ on Enterprise). These are pre-rendered characters — you choose the outfit and setting from what Synthesia has filmed. The quality ranges from good to excellent depending on the avatar. The best ones are indistinguishable from a medium-quality corporate video shoot in the background; the weaker ones look polished but slightly plastic in facial close-ups.
A subset of stock avatars built on Synthesia’s Express-2 model. The difference is behavioral: standard avatars are relatively static, with minimal body movement beyond small head motions. Express-2 avatars gesture naturally, nod, and shift weight. More critically, they adjust micro-expressions — eyebrow raises, brief smiles, varying eye contact — based on the emotional content of the script. A sentence like “this is critical safety information” gets a different expression than “congratulations on completing module one.” The system reads tone and adjusts accordingly. Express-2 avatars are included in all paid plans. They are the right default for anything you plan to share externally.
The most significant recent addition. Customizable avatars use diffusion model technology (Synthesia integrates with Veo 3 and similar generation infrastructure) to let you prompt the avatar’s appearance and environment in natural language. Type “high-vis vest and steel-toe boots in a construction site setting” and the avatar generates into that context. Type “hospital scrubs with a clinical background” and you get a medical training presenter. The same avatar can serve a manufacturing safety module and a new-hire welcome video without any filming. This directly eliminates one of the biggest practical limitations of stock avatar libraries — the mismatch between a business casual stock character and an industrial training context.
Upload a photo or a short webcam video, record a consent statement, and Synthesia trains a personal avatar from your likeness with voice cloning. The result is a digital twin that speaks any script in your voice across 100+ languages. Starter plan includes 3 personal avatars; Creator includes 5; Enterprise is unlimited. The consent workflow is mandatory and non-skippable — Synthesia requires auditable consent before generating any personal avatar, which is both legally sound and ethically important.
Professional studio-produced avatars captured with high-end cameras and lighting, sold as a $1,000/year add-on for Enterprise subscribers. The quality jump over standard stock is significant and immediately visible — these read as broadcast-quality rather than production-quality. Used primarily by large enterprises for executive communications and external brand presence.
The Express-2 avatars are genuinely impressive in motion. Watch one deliver a training script and the first reaction is usually “that’s better than I expected.” The gestures are plausible rather than rehearsed-looking, the eye contact patterns feel natural, and the micro-expressions prevent the glassy stare that plagued first-generation AI avatars.
Where the illusion breaks down is in extended close-up and in emotional extremes. In medium shot — chest up, as most Synthesia templates render — the realism holds. Zoom in to a head-and-shoulders crop and you start to see the texture rendering fall apart around the hairline and neck. Ask the avatar to express strong emotion — genuine laughter, frustration, grief — and the expression plateaus at “professionally warm.” The Express-2 system reads emotional content and adjusts, but the range is deliberately constrained. You will not mistake these for human video in a scrutinizing environment.
The practical implication: Synthesia works best for corporate contexts where the contract with the viewer is already professional rather than personal. A training module on compliance procedures benefits from a calm, clear, professional presenter — which is exactly what Express-2 delivers. A CEO keynote or a brand campaign that depends on authentic human connection requires actual humans.
The Customizable avatar feature introduces a new dimension of physical expressiveness: prompted actions. You can script an avatar to “walk to the whiteboard,” “place the device on the table,” or “point at the diagram” — short movement sequences that break the talking-head format. These B-roll action sequences are generated alongside the A-roll explanation and stitched together in the editor. The result isn’t cinematic, but it directly solves the “show don’t tell” problem in technical training: you can demonstrate a procedure with the same avatar explaining it, without separate footage.
Language localization is the feature that separates Synthesia’s enterprise use case from every competitor’s. The platform supports 140+ languages and accents with a library of 400+ AI voices. On Enterprise plans, existing videos can be translated and re-localized with one click — the system re-dubs the audio, re-syncs the avatar’s lip movements to the target language, and updates auto-captions, all automatically.
The practical workflow for a global L&D team: build the master training video once in English, then generate localized versions for French, German, Japanese, Portuguese, Arabic, and any other language your workforce needs. Each localized version has the avatar speaking the language natively — not just subtitled, but lip-synced. The turn-around from English master to ten localized versions is measured in hours, not weeks. Traditional localization through dubbing studios or re-shoots might take three to six weeks per language and cost several thousand dollars per video per language. At Synthesia’s scale, ten languages means one afternoon.
The caveats are real. Lower-resource languages have fewer voice options and the quality can be noticeably lower than major Western languages. The translation itself uses AI — which means culturally idiomatic text can produce odd output in languages with very different sentence structure. The best practice is to have a native speaker review the script before generating rather than after, since a script-level correction is much cheaper than re-generating ten scenes. But the directional capability is real and valuable: the language barrier to global video training is genuinely lower with Synthesia than with any other platform we’ve tested.
Before you localize your first video, identify a native-speaker reviewer for each target language. Their job is to review the AI-translated script before you generate, not after. Catching a mistranslation at the script stage costs five minutes; catching it after generation costs five minutes plus re-render time. For regulated content (compliance, safety), this review step is non-negotiable.
A typical Synthesia production from scratch to published video follows a consistent arc. Understanding the stages — and where the platform helps versus where it needs human judgment — sets realistic expectations.
The AI Script Generator handles first drafts well. Feed it a topic, a PDF, or a URL and it produces structured scene-by-scene text in minutes. The output is functional but often bland — it covers the topic but lacks the voice of your organization. The most effective teams treat the AI draft as a starting skeleton and spend 80% of their editing time on tone, specificity, and cutting: AI generators tend to overwrite. A 10-minute training video’s worth of script should compress to under 1,200 words. If your first draft is longer, it will feel padded.
Pick your avatar (Expressive by default), set your template or custom background, configure language and voice. Synthesia’s template library covers most common corporate use cases: onboarding, compliance, product training, executive announcements. Templates set scene layout, typography, and background style — use them unless you have a strong visual brand reason not to. The time spent custom-building what a template gives you for free is rarely worth it.
Generation time scales with video length and plan tier. A two-minute video typically renders in two to four minutes on Creator; Enterprise gets priority rendering that’s faster under load. The generation is asynchronous — you can start another video or close the tab. Synthesia sends an email when it’s done. This is comfortable for batch production but slightly frustrating for single videos where you’re waiting to review.
Review focuses on pronunciation errors (names, technical terms, acronyms), timing issues where the avatar’s speech pace feels off, and expression mismatches. Synthesia’s editor lets you tweak individual scenes without re-generating the whole video — a critical quality-of-life feature when you have a ten-scene video and one scene needs adjusting. Re-generating a single scene takes the same 2-3 minutes as a short video.
Synthesia’s publish options include a hosted video page (password-protected or public), direct download, embed code, and SCORM export for LMS. The hosted page has built-in analytics. Embeds auto-update when you publish a new version — which means you can fix a video after it’s embedded in your LMS or intranet without touching the embed code. This is quietly one of the best features for compliance teams who need to update safety videos regularly.
![]()
The brief: replace a mix of recorded Zoom calls, PDF walkthroughs, and outdated screen-capture videos with a consistent, branded onboarding library available in six languages (English, French, German, Spanish, Portuguese, Japanese). Previous production: one outside agency, eight-week production cycle per module, $8,000-12,000 per video.
With Synthesia, the L&D team built a single set of master scripts in English, applied a branded template with company colors and logo, and assigned a personal avatar of the Head of People to deliver every module. Generation of all 12 English videos took three days (mostly script editing). Localization to five additional languages took another two days — the AI translation was reviewed by internal native speakers before generation, catching four idiomatic issues in French and one technical term error in Japanese before any video rendered.
Total turnaround: 8 working days from first script to 72 published videos (12 modules × 6 languages). When the compliance module was updated three months later with regulatory changes, the Head of People’s personal avatar re-delivered the updated script — visual consistency maintained without a re-shoot.
The problem: product shipped new features every two weeks. Sales enablement was sending text emails summarizing changes. Open rates were poor and reps were missing key messaging. The ask: turn feature release notes into short video briefings that reps would actually watch.
The workflow: the PM writes release notes. The sales enablement manager runs them through Synthesia’s Script Generator to produce a 300-word briefing script. A stock Expressive avatar (same one used every week for brand consistency) delivers the briefing against a product screenshot background. Total production time from release notes to published video: 35 minutes. The video embeds in the existing sales enablement platform — the same embed link updates automatically each week.
The interactive video feature (available on Creator) added a quiz at the end of each briefing: three questions verifying comprehension of the new feature. Completion rates and quiz scores feed back into the built-in analytics dashboard. After six weeks, the L&D team had quantitative data showing which features were confusing reps — triggering focused follow-up coaching sessions.
The brief: existing safety training existed as English-only PDFs. A compliance audit flagged the absence of translated training as a liability gap — workers whose primary language wasn’t English couldn’t demonstrate documented comprehension. The traditional fix (professional translation + video re-shoot per language) was quoted at $45,000 and ten weeks.
Synthesia’s Customizable avatar feature was the unlock here. The safety trainer wrote the scripts in English, then the AI translated to the seven target languages (Spanish, Polish, Romanian, Vietnamese, Tagalog, Arabic, Mandarin). The avatar was prompted with “high-vis vest, safety helmet, manufacturing floor background” — creating visual context appropriate to the content rather than a generic business casual presenter. The script included action sequences: “walk toward the emergency station,” “demonstrate the lockout procedure” — short movements generated alongside the explanation.
SCORM packages were generated for each language version and loaded into the plant’s existing LMS. Completion tracking per worker, per language, with quiz results, gave the compliance team auditable documentation of trained status. The whole project delivered in twelve working days at a total platform cost under $2,000.
Synthesia’s enterprise positioning is one of the strongest in the AI video space and it isn’t accidental. The company has invested heavily in the compliance stack because their target customer — L&D managers and CHROs at regulated companies — cannot buy software that fails a security review. As of 2026, Synthesia holds SOC 2 Type II and ISO 27001 certifications (with active GDPR compliance), and the company offers HIPAA Business Associate Agreements for healthcare customers on Enterprise plans.
The consent workflow for personal avatars deserves explicit mention. Synthesia requires a recorded verbal consent statement from any person whose likeness is used to generate a personal avatar. This is auditable, time-stamped, and stored. The company has been proactive about AI deepfake concerns well ahead of regulatory requirements — not because the law required it, but because enterprise procurement teams started asking for it in 2023. The infrastructure was in place before it became legally necessary in some jurisdictions.
Enterprise-grade features on the top tier include SAML/SSO (single sign-on for corporate identity management), SCORM and xAPI export for LMS integration with Cornerstone, Docebo, SAP SuccessFactors, Workday, and TalentLMS, role-based access control, version history, collaborative review and approval workflows, brand kit management (centralized fonts, colors, logos that cascade across all videos), and a dedicated customer success manager. The combined package makes procurement straightforward for organizations that have run this gauntlet before.
If LMS integration is your primary use case, plan for Enterprise from the start. SCORM export — the standard format for loading training content into corporate learning management systems — is not available on Creator or Starter. Evaluating the platform on a Creator trial and then discovering SCORM requires a contract upgrade is a common frustration for L&D teams.
a/synthesia b/heygen
HeyGen is Synthesia’s most direct competitor and the comparison that comes up most in L&D procurement discussions. Both platforms do AI avatar video from scripts. The differences are real and matter depending on your use case. See our full HeyGen review at /ai/heygen/.
Verdict: Synthesia for regulated enterprise L&D where compliance certifications, SCORM, and audit logging are hard requirements. HeyGen if you’re budget-conscious, doing social/marketing content, or need the most lifelike avatar realism. Both are legitimate; the compliance stack is what breaks the tie for enterprise procurement.
bench –tool=synthesia,heygen –metric=compliance,content-type,scale enterprise L&D context

No tool review is useful without an honest accounting of the failure modes. Synthesia has real limitations that matter depending on your use case.
Synthesia is a talking-head platform. Even with Customizable avatars and prompted actions, the fundamental output is a person speaking to camera with a background. It is not a cinematic production tool, not a narrative storytelling tool, and not a tool for anything that requires environmental complexity, multi-character interaction, or emotional authenticity that exceeds “professional warmth.” If your video needs to feel real in an interpersonal sense — a message from a leader who their team has deep trust with, a brand film requiring genuine human connection — Synthesia will feel hollow. The AI video is a productivity tool for informational content; it is not a substitute for genuine human expression when that expression is the point.
The Starter plan includes 10 minutes per month of generated video. That sounds like a lot until you realize it’s 10 minutes of finished video, not 10 minutes of script. A single 5-minute training module with one revision uses your monthly allowance in one afternoon. Creator’s 30 minutes per month is more workable for a single active project, but a team producing a library of training content will hit the ceiling regularly. Enterprise’s unlimited minutes reflect what the platform actually needs to be useful at scale.
AI voice synthesis still stumbles on proper nouns, acronyms, industry jargon, and brand-specific terminology. Your product is called “QuikAssess” — the platform will probably mispronounce it. The fix is phonetic spelling in the script (“Kwik-Assess”) or using the pronunciation editor, but this adds friction and requires careful review before publishing anything with names or technical terms. In a 10-module compliance library, that’s a non-trivial review burden per generation cycle.
For internal corporate use — compliance training, onboarding, process walkthroughs — the AI quality is fine and most viewers accept the contract quickly. For anything consumer-facing, brand-positioned, or in a context where the viewer has a high-trust relationship with the speaker, the AI is detectable and can undercut credibility. Synthesia explicitly acknowledges this: their marketing positions the platform for training and internal comms, not advertising or brand campaigns. The positioning is honest and the limitation is real.
Synthesia’s roadmap includes “Video Agents” — AI avatars that can respond dynamically to viewer input, essentially a conversational AI presented as a video character. This would be a significant upgrade for interactive training use cases. As of mid-2026 it remains in preview status. The platform is genuinely useful without it, but the gap between “video with embedded quiz” and “video that responds to you” is meaningful, and the timeline is unclear.
Synthesia requires consent for personal avatar creation and records it. But the governance around who can create personal avatars using a colleague’s likeness within an organization is your responsibility, not the platform’s. Before enabling personal avatar creation for your team, establish a clear internal policy: who can commission a personal avatar of whom, what approval is required, and how avatars are retired when someone leaves the company. Skipping this step has caused real reputational and legal issues for early enterprise adopters.
The free tier delivers 10 minutes of generated video per month with 9 avatars and a Synthesia watermark. It’s genuinely useful for evaluation. You will hit the ceiling in one productive afternoon, which is the point — it’s a trial, not a working tier.
Starter at $29/month (or $18/month on annual billing) removes the watermark, expands to 125+ avatars, adds 3 personal avatar slots, video download, and AI Dubbing. Still limited to 10 minutes per month, which is the plan’s main constraint. Right for solo content creators testing the workflow before committing to scale.
Creator at $89/month (or $64/month annually) is the first genuinely workable production tier. 30 minutes per month, 180+ avatars including the full Expressive library, 5 personal avatars, multiple avatars per scene, interactive video with quizzes and CTAs, API access, and priority support. For a team actively building a training library, this is the minimum viable tier.
Enterprise pricing is custom — contact sales, no public number. Third-party procurement data (Vendr) puts the median enterprise contract at around $30,000 per year. What you get: unlimited minutes, 240+ avatars, unlimited personal avatars, 1-click translation across 80+ languages, SAML/SSO, SCORM export, LMS integrations, brand kits, live collaboration, dedicated CSM. If you’re a 50+ person company with an active L&D function, the per-video unit economics at Enterprise are compelling — a $30k annual contract across 200 training videos works out to $150/video, versus $8,000-12,000 per traditionally-produced video.
Studio Avatar add-on: $1,000/year for annual Enterprise subscribers. This gets you a professional studio-captured avatar of one real person — broadcast quality, dramatically more realistic than standard stock. For C-suite communications, it’s worth the math: one studio shoot for a year of consistent, updatable executive video is cheaper than scheduling a CEO in front of a camera every time a policy changes.

Laura Overton@lauraoverton · learning analystWe produced 47 compliance modules in 6 languages in the time it used to take us to produce 3 in English. Synthesia didn’t change our strategy — it removed the production bottleneck that was forcing us to deprioritize video entirely.
Josh Bersin@josh_bersin · HR analystThe enterprise L&D market has been waiting for a video platform that passes IT security review, works in every language, and doesn’t require a video crew. Synthesia is it. The compliance story — SOC 2, ISO 27001, SCORM — isn’t glamorous but it’s what actually unlocks procurement in large organizations.
Lenny Rachitsky@lennysan · productSynthesia is interesting as a case study in platform positioning. They chose “enterprise L&D” before that was a hot category, built the compliance features nobody was asking for yet, and now they own the conversation. HeyGen makes better avatars. Synthesia has the enterprise contracts.
Claire Lew@clairejlew · CEO Know Your TeamHonest take: Synthesia is excellent at what it does and I still wouldn’t use it for anything where the human connection is the whole point. Executive all-hands, personal announcements, hard conversations — those need real people. Use the tool for what it’s built for.
Depends entirely on context. Synthesia wins for enterprise L&D with SOC 2/ISO 27001 requirements, SCORM export, and formal LMS integration. HeyGen wins for creative content, social media, and buyers who want the most lifelike avatar quality at a lower price point. Both are legitimate; most L&D teams land on Synthesia because compliance certifications are easier to clear in procurement.
Yes. Personal avatars are available on Starter (3 avatars) and Creator (5 avatars). The process requires uploading a photo or short video and recording a verbal consent statement. Generation takes minutes. The result speaks any script in your voice in 100+ languages. Studio-quality personal avatars are a $1,000/year add-on for Enterprise subscribers.
Yes — but only on Enterprise. SCORM export, xAPI support, and direct LMS integrations (Cornerstone, Docebo, SAP SuccessFactors, Workday) are Enterprise-tier features. If SCORM is a hard requirement, factor Enterprise pricing into your evaluation from the start.
The platform supports 160+ languages and accents across its voice library. One-click video translation (where the avatar’s lips re-sync to the new language automatically) covers 80+ languages on Enterprise. If you need a specific lower-resource language, verify availability before committing — not all 160+ have the same avatar lip-sync quality.
Yes, under scrutiny. Expressive avatars are significantly more convincing than earlier generations and work well in corporate training contexts where the viewer’s expectation is “professional presenter,” not “movie star.” In closeup, in emotional extremes, or in consumer-facing content where the viewer expects authentic human connection, the AI quality is detectable. Synthesia is designed for informational corporate content, not brand campaigns or personal communication.
Free: 10 minutes/month. Starter: 10 minutes/month (the main reason to upgrade to Creator for active producers). Creator: 30 minutes/month. Enterprise: unlimited. Minutes count finished video output, not recording time. A 5-minute video with one re-generate uses 10 minutes of your monthly allowance.
Technically yes, but it’s not what the platform is designed for. Synthesia’s output reads as corporate — polished, professional, slightly formal. Social media content (especially short-form) rewards authenticity and personality that AI avatars can’t reliably deliver. For social media, HeyGen or tools specifically built for creator content are better fits.
Synthesia holds SOC 2 Type II and ISO 27001 certifications, offers HIPAA BAAs on Enterprise, and supports SAML/SSO. Video pages can be password-protected or restricted to SSO-authenticated users. For regulated industries (healthcare, financial services, government contractors), the compliance stack is a genuine differentiator. For government or defense requiring on-premise deployment, neither Synthesia nor HeyGen currently offers air-gapped options.
Yes, with limitations. Creator allows 1 editor + 5 guests (view/comment). Enterprise adds live collaboration for multiple editors and formal review/approval workflows. Real-time co-editing is functional but not yet as fluid as dedicated collaboration tools. For teams larger than three active video editors, expect occasional sync friction.
Synthesia is the most complete solution for organizations that need to produce professional training and communications video at scale, across languages, within enterprise security requirements. The compliance story is real — SOC 2 Type II, ISO 27001, HIPAA BAAs, SAML/SSO — and it unlocks procurement conversations that would otherwise stall indefinitely. The avatar quality, particularly the Express-2 expressive avatars and the new Customizable avatar actions, is genuinely impressive for its purpose.
The ceiling is clear: Synthesia is a talking-head platform for informational content. It is not a cinematic tool, not a personal branding platform, not a substitute for authentic human communication when the human is the point. The minute allowances on lower tiers are tighter than they look, SCORM export requires Enterprise, and the AI realism will not fool a discerning viewer. Within those boundaries, the ROI case is strong — corporate video that used to cost $10,000 and eight weeks now costs $150 and three days. For L&D teams and enterprise comms, that math is the whole argument.
Every verified price, limit, and model change we have tracked for Synthesia.
One email when Synthesia changes price or limits. No account, no spam.